回想一下,在前面几章中,就sparkSQL1.1.0基本概念、执行架构、基本操作和有用工具做了基本介绍。 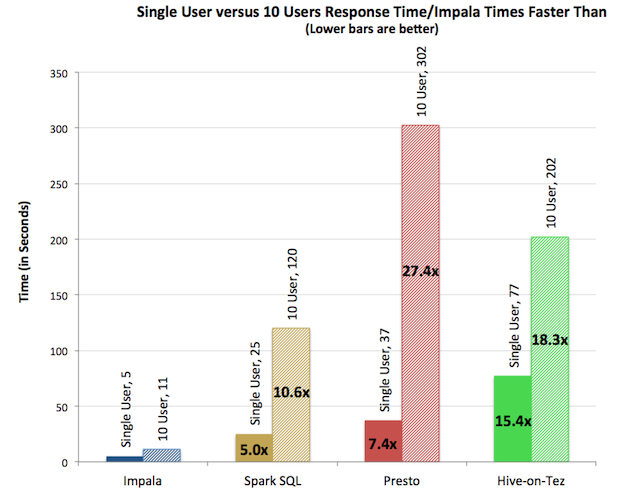
基本概念:
- SchemaRDD
- Rule
- Tree
- LogicPlan
- Parser
- Analyzer
- Optimizer
- SparkPlan
- 执行架构:
- sqlContext执行架构
- hiveContext执行架构
- 基本操作
- 原生RDD的操作
- parquet文件的操作
- json文件的操作
- hive数据的操作
- 和其它spark组件混合使用
- 有用工具
- hive/console的操作
- CLI的配置和操作
- ThriftServer的配置和操作
因为时间仓促,有非常多地方来不及具体,特别是第三章和第九章;另外另一些新的特性没有介绍,比方列存储的实现过程、CODEGEN的源代码分析等,将在兴许的版本号逐步完好。
从整体上来说,因为CLI的引入,使得sparkSQL1.1.0在易用性方面得到了极大地提高;而ThriftServer的引入,方便了开发人员对基于SparkSQL的应用程序开发;hive/console的引入,极大地方面了开发人员对sparkSQL源代码的改动和调试;还有json数据的引入,不但扩充了sparkSQL的数据来源,同一时候对嵌套数据開始做了尝试。
从Spark1.1.0開始。sparkSQL逐渐開始像是一个产品了。而不像spark1.0.0。感觉像是一个測试品。当然。因为sparkSQL项目的启动时间比較晚,到如今为止还不到一年,在非常多方面还存在着不足:
- SQL-92语法的支持度。sparkSQL使用了一个简单的SQL语法解析器,对于一些复杂的语法没办法解析,比方三个表进行join的时候。不能一次性join,而要通过两两join后再join一次;
- cost model 。尽管sparkSQL的catalyst在最初设计的时候就考虑到了cost model。但在如今的版本号还没有引入。我们相信,未来引入cost model之后。sparkSQL的性能将得到进一步地提升;
- 并发性能,从impala得到的信息,sparkSQL的并发性能和impala相比。还是有不少的差距。这将是sparkSQL的一个发展方向。
匆匆忙忙中,sparkSQL1.1入门第一版就先在这里结束吧。特别感谢一下站点或博客提供了相关的知识: